Coroutine 中文译为协程,协程的概念现在出现的越来越多。Programming languages with native support 这里面列出了原生支持 Coroutine 的语言,其中有我们熟悉的 Go、Python 等。但是,C、C++ 不在其列,没有语言原生层面的支持,热衷于 “Do It Yourself” 的 C/C++ 程序员们创造了非常多的 Coroutine Library。我们熟悉的有腾讯的 libco、brpc 的 bthread、云风的 coroutine 等。本文旨在探讨 Coroutine 实现上最基础的部分,即 Context Switch。
1. Why Coroutine
我们知道现代操作系统中线程是抢占式的,由内核来负责线程调度和切换。一般来说,这个切换发生在时间中断和系统调用时,这样子带来的好处是当控制流不得不因为一些阻塞操作(比如网络 IO)而中断时,我们无需考虑逻辑流是否需要主动中断。
什么意思呢?假设我们的服务端程序有 10 个线程,每个线程持有一个连接,所在机器上只有一个 CPU 核心。那么当其中一个线程因为阻塞在等待连接上数据到来时,内核会将该主动将 CPU 让给就绪态的线程执行逻辑。在这个过程中,该线程的控制流阻塞在了等待数据上,但是逻辑流无需在代码上做额外处理(我们不需要主动声明让出 CPU 控制权),因为我们知道内核会为我们接管这一切,CPU 不会空转,会有就绪线程被调度到 CPU 上运行。这时,逻辑流和控制流是等价的。
一切看起来很美好,直到我们需要直面性能问题。当我们只需要同时处理 10 个连接时,我们让 10 个线程来处理,当我们需要同时处理 10K 个连接时,我们能用 10K 个线程来处理吗?答案当然是不可以,至少现在不可以。原因自然是老生常谈的上下文调度与切换、内存同步等开销。Measuring context switching and memory overheads for Linux threads 这篇文章测量了在现在(2018 年)线程上下文切换的代价:
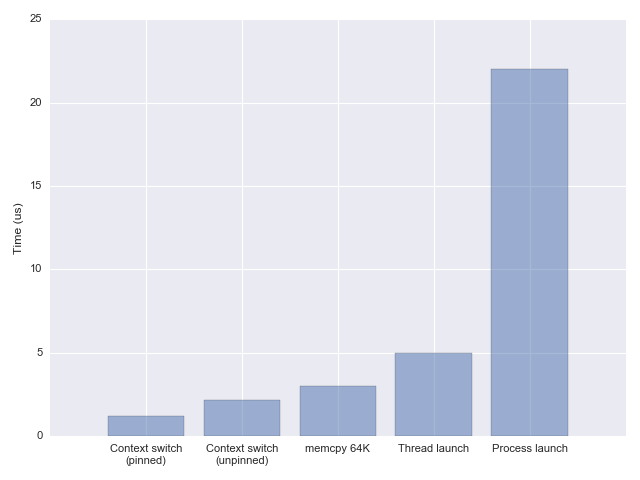
简单来说,线程的上下文切换只比在内存中复制 64 K 数据稍快点。看起来似乎已经够快了,但是从数量级上与 Latency Numbers Every Programmer Should Know 给出的数据比较,着实不够快,至少试图在一个机器上跑 10K 个线程不是一件有意义的事情。

那该怎么办呢?我们可以使用异步操作:通过回调函数来响应被阻塞的操作结果,然后继续被中断的逻辑。不过让我们回到逻辑流和控制流的话题,使用异步回调,就意味着我们需要将原本连续的逻辑流打破,使用各种回调来组织逻辑,而为了在回调之间保证控制状态(数据信息)的一致性,需要用户自己维护每个回调阶段的状态。这样子,逻辑流和控制流不再等价,我们付出的代价是手动维护控制状态信息。
为了避免异步编程的困难,我们再次拿起了协程的概念,通过协程用同步的方式来写异步的程序。这次,我们同样在逻辑流中该阻塞的地方阻塞,不过不同于线程由内核调度走,协程会主动让出执行权,交由其它就绪协程执行,等阻塞的操作结束后,调度器会重新把执行权还给该协程,这样子,用户的逻辑流和控制流再次等价。
从上面的描述可以看出,实现一个协程库的核心在于三方面:上下文切换、协程栈(本文只讨论有栈协程)、调度器。而上下文切换的代价足够小正是我们使用协程而不是线程的直接驱动力。实现协程上下文切换有很多种方法,本质要做的都是保存和恢复寄存器和栈信息,可供选择的有:boost.context、setjmp、sigaltstack、ucontext,不过 boost.context 是最快的,bthread 也是使用 boost.context,下面我们就以 bthread 的代码为准,分析如何做到协程的 Context Switch。
2. Stack Frame
为了理解协程的 Context Switch,我们首先得熟悉程序中函数调用背后的知识,也就是 Stack Frame。首先我们列出下面我们用到的几个汇编指令。
| 汇编指令 | 解释 |
|---|---|
| push ebp | 将 ebp 寄存器的值 push 到栈上 |
| move ebp, esp | 将 esp 寄存器的值赋给 ebp 寄存器 |
| sub esp, X | 将 esp 寄存器中的值减去 X |
| pop ebp | 将当前栈顶值 pop 给 ebp 寄存器 |
| ret | 将当前栈顶值弹出给 eip 寄存器 |
当然,我们也要复习下计算机中的几个关键寄存器:
| 寄存器(32位) | 含义 |
|---|---|
| eip | 指令寄存器 |
| esp | 堆栈顶指针 |
| ebp | 堆栈基指针 |
OK,有了这些知识储备,我们可以开始探究函数调用过程中究竟发生了什么事,我们思考的重点就是:
- 编译器如何为我们处理调用者(Caller)和被调用者(Callee)的 Stack Frame?
- Callee 如何知道返回后执行的地址?(这是非常关键的问题,因为 Coroutine Context Switch 的核心就是如何做到从一个 Coroutine 切出,切回时能继续在切出的地方继续执行)
我们的例子如下:
int add(int x, int y) {
int res = x + y;
return res;
}
int main() {
add(1, 2);
return 0;
}
那么,一个典型的 Caller Stack Frame 是这样的:
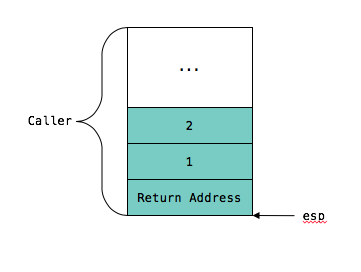
相应的汇编代码为:
push 2
push 1
// 汇编为 call _add,翻译如下:
push eip + 2 // eip + 2 即为 Return Address
jmp _add
可以看出,函数调用过程中将其参数从右到左反向压入栈中,以此到达传参的目的,之后再将 Caller 的返回地址压栈,然后执行流程就转到 Callee 了。
编译器为我们生成的 Callee Stack Frame 如下:

汇编代码为:
push ebp // 将当前 ebp 寄存器的值(Caller Stack Frame 的栈基指针)push 到栈中
move ebp esp // 将当前 esp 寄存器的值(即 Callee Stack Frame 的栈基指针)放到 ebp 寄存器中保存
sub esp X; // 将 esp 寄存器(栈顶指针)往下移 X,为本地变量预留出栈上空间
这段代码的主要目的为:
- 将旧的 ebp push 到栈中(函数调用结束后会恢复该值)
- 将当前 Stack Frame 的栈基指针赋值给 ebp 寄存器(这样做的目的是编译器可以通过 ebp 寄存器的值定位到 Caller 参数和 Callee Local Variable,当然这是一个比较复杂的话题,不过与下面要讨论的 Coroutine Context Switch 关系不大,在此就不展开解释啦)
- 为本地变量分配空间。
之后,就是函数内部逻辑的处理了,下面我们最后来看一下函数调用返回时,编译器是如何为我们处理的:
mov esp ebp // 将 esp (栈顶指针)赋值为 ebp 寄存器(即之前保持的栈基指针)
pop ebp // 将当前栈顶值(即 old ebp)pop 给 ebp 寄存器(这样子就在函数调用后恢复了 ebp 寄存器)
// ret 8 可理解为以下汇编代码
ret // 将当前栈顶值(即 Return Address)pop 给 eip 寄存器(指令寄存器)
add esp, 8 // 将 esp(栈顶指针)上移 8(Caller 为函数参数分配的空间大小)
这样子,我们就基本理解了 Caller 和 Callee 是如何运作的,以及对应的 Stack Frame Layout。
现在我们可以回答最开始提出的第二个问题:即 Callee 是如何知道返回后的地址?答案就是 Caller Stack Frame 中的 Return Address。而这,也是实现 Coroutine Context Switch 的关键:
我们只需要将待切换 Coroutine 的函数地址保存在 Return Address 中,当前调度函数结束之后,会自动切换到这个地址上执行。
3. Context Switch
讨论协程的上下文切换前不妨先回忆下线程上下文切换的过程。
每个线程都拥有一个用户态堆栈(user-mode stack)和内核态堆栈(kernel-mode stack)。线程上下文切换的过程就是把用户态堆栈和寄存器的信息保存在内核态堆栈中,再恢复待调度线程的寄存器和用户态堆栈。当然,这个过程是陷入到内核态后,由操作系统和硬件共同协作完成的。由此可见,一个线程的执行状态由两个基本要素组成:寄存器、栈信息。同样的,协程上下文切换过程中本质上就是对寄存器和栈信息的保存与恢复。于是,我们来看下 bthread(boost.context)是如何做的。
bthread 中与上下文切换相关的操作分为两个步骤:
// 跳转 bthread context
intptr_t BTHREAD_CONTEXT_CALL_CONVENTION
bthread_jump_fcontext(bthread_fcontext_t * ofc, bthread_fcontext_t nfc,
intptr_t vp, bool preserve_fpu = false);
// 创建 bthread context
bthread_fcontext_t BTHREAD_CONTEXT_CALL_CONVENTION
bthread_make_fcontext(void* sp, size_t size, void (* fn)( intptr_t));
在看这两个函数的具体汇编实现之前,先列出后续用到的几个寄存器信息(以 x86_64 代码为例,好读点):
| 寄存器(64位) | 含义 |
|---|---|
| rdi | 保存 Caller 第一个参数 |
| rsi | 保存 Caller 第二个参数 |
| rdx | 保存 Caller 第三个参数 |
| rcx | 保存 Caller 第四个参数 |
| rax | 保存 Callee 第一个返回值 |
| rsp | 堆栈顶指针 |
| rbp | 堆栈基指针 |
| rip | 指令寄存器 |
我们先来看 bthread context 的创建:
__asm (
".text\n"
".globl bthread_make_fcontext\n"
".type bthread_make_fcontext,@function\n"
".align 16\n"
"bthread_make_fcontext:\n"
" movq %rdi, %rax\n" // 将 rdi 的值(即第一个参数 sp,也就是协程栈空间的地址)赋值给 rax,此时 rax 指向用户自定义协程栈的地址
" andq $-16, %rax\n" // 将 rax 下移 16 字节对齐
" leaq -0x48(%rax), %rax\n" // 将 rax 下移 0x48,即留出 0x48 个字节用于存放 Context Data
" movq %rdx, 0x38(%rax)\n" // 将 rdx 的值(即第三个参数 fn,也就是协程初始化后的运行函数)赋值给 (rax) + 0x38 的位置上
" stmxcsr (%rax)\n" // 存储 MMX Control 信息
" fnstcw 0x4(%rax)\n" // 存储 x87 Control 信息
" leaq finish(%rip), %rcx\n" // 计算 finish 对应的指令地址,存放在 rcx 中
" movq %rcx, 0x40(%rax)\n" // 将 rcx 的值赋值给 (rax) + 0x40 的位置上
" ret \n"
"finish:\n" // 函数退出
" xorq %rdi, %rdi\n"
" call _exit@PLT\n"
" hlt\n"
".size bthread_make_fcontext,.-bthread_make_fcontext\n"
".section .note.GNU-stack,\"\",%progbits\n"
);
bthread_make_fcontext 的汇编还算容易懂,基于此,我们可以画出 Coroutine Stack 初始化后的 Layout:
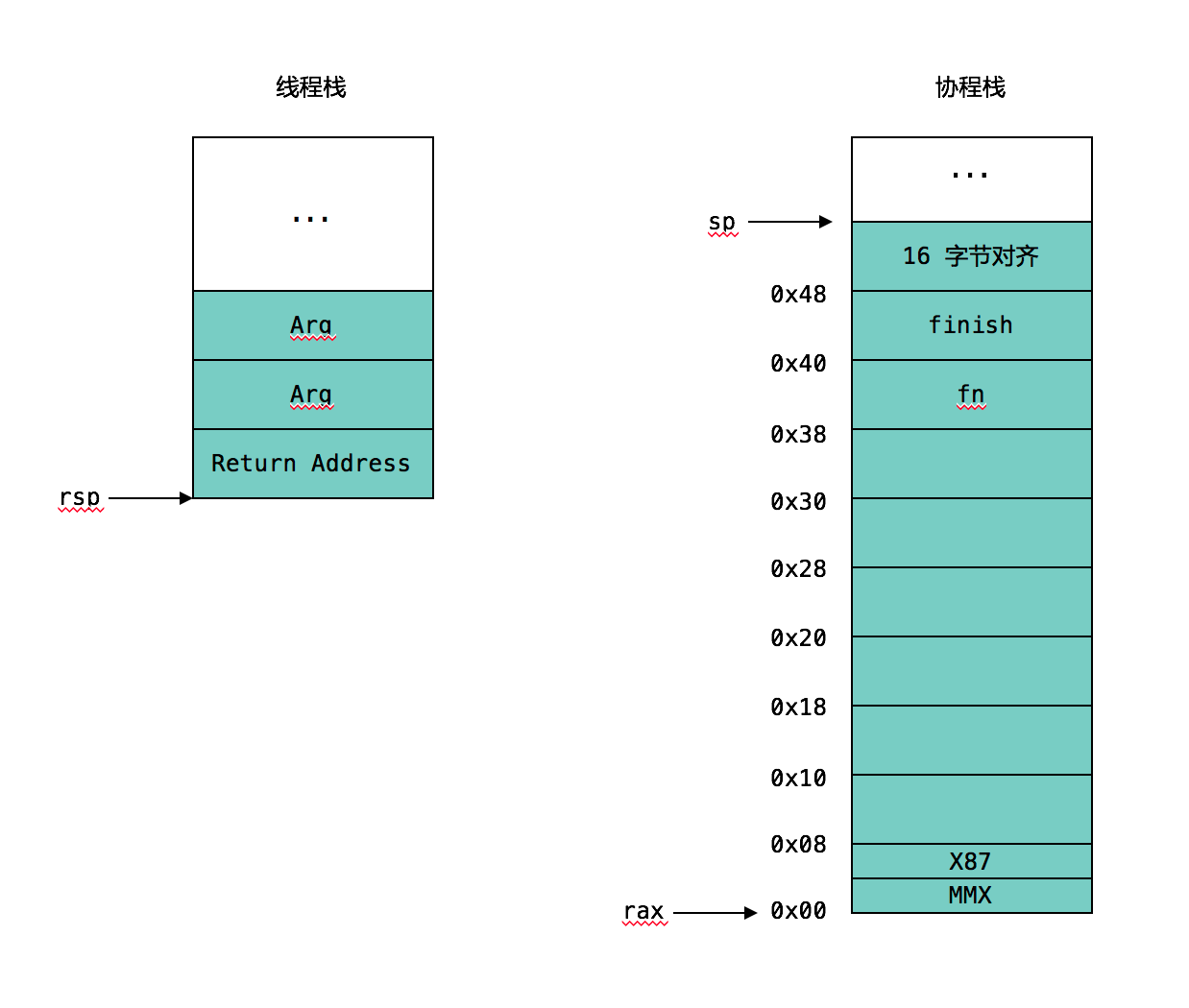
其中 rax 寄存器就是 bthread_make_fcontext 的返回值,也就是 bthread_fcontext_t。
终于到 Context Switch 的环节了,我们来看 bthread_jump_fcontext 的代码:
__asm (
".text\n"
".globl bthread_jump_fcontext\n"
".type bthread_jump_fcontext,@function\n"
".align 16\n"
"bthread_jump_fcontext:\n"
" pushq %rbp \n" // push rbp 寄存器值到当前协程栈中
" pushq %rbx \n" // push rbx 寄存器值到当前协程栈中
" pushq %r15 \n" // push r15 寄存器值到当前协程栈中
" pushq %r14 \n" // push r14 寄存器值到当前协程栈中
" pushq %r13 \n" // push r13 寄存器值到当前协程栈中
" pushq %r12 \n" // push r12 寄存器值到当前协程栈中
" leaq -0x8(%rsp), %rsp\n" // rsp (栈顶指针)下移 8 字节
" cmp $0, %rcx\n" // 比较 rcx(第四个入参,即 preserve_fpu,默认为 false)与 0
" je 1f\n" // rcx = 0(即 preserve_fpu 为 false)则跳转
" stmxcsr (%rsp)\n" // 保存 MMX Control 信息
" fnstcw 0x4(%rsp)\n" // 保存 x87 Control 信息
"1:\n"
" movq %rsp, (%rdi)\n" // 将 rsp(栈顶指针)保存在 rdi 寄存器所指向的值(即第一个入参,ofc)中
" movq %rsi, %rsp\n" // 将 rsp(栈顶指针)赋值为 rsi(即第二个入参,nfc)
" cmp $0, %rcx\n"
" je 2f\n"
" ldmxcsr (%rsp)\n"
" fldcw 0x4(%rsp)\n"
"2:\n"
" leaq 0x8(%rsp), %rsp\n" // rsp(栈顶)指针上移 8 字节
" popq %r12 \n" // pop 栈顶元素,赋值给 r12
" popq %r13 \n" // pop 栈顶元素,赋值给 r13
" popq %r14 \n" // pop 栈顶元素,赋值给 r14
" popq %r15 \n" // pop 栈顶元素,赋值给 r15
" popq %rbx \n" // pop 栈顶元素,赋值给 rbx
" popq %rbp \n" // pop 栈顶元素,赋值给 rbp
" popq %r8\n" // pop 栈顶元素,赋值给 r8
" movq %rdx, %rax\n" // 将 rdx 赋值给 rax,作为返回值
" movq %rdx, %rdi\n" // 将 rdx 赋值给 rdi,作为接下来的入参
" jmp *%r8\n" // 跳转到 r8 寄存器指示的位置处继续执行
".size bthread_jump_fcontext,.-bthread_jump_fcontext\n"
".section .note.GNU-stack,\"\",%progbits\n"
);
Context Switch 的过程就显得有些复杂了。当然,核心思想还是保持和恢复两个 Coroutine 的寄存器和栈信息。不过,这里需要针对被调度 Coroutine 分为两种情况讨论:首次调度、非首次调度。我分别画出相应的 Stack Frame Layout 加以说明:
首次调度是指该 Coroutine 的 Stack Frame 如 make_fcontext 中画出的那样,于是 Context Switch 意味着:
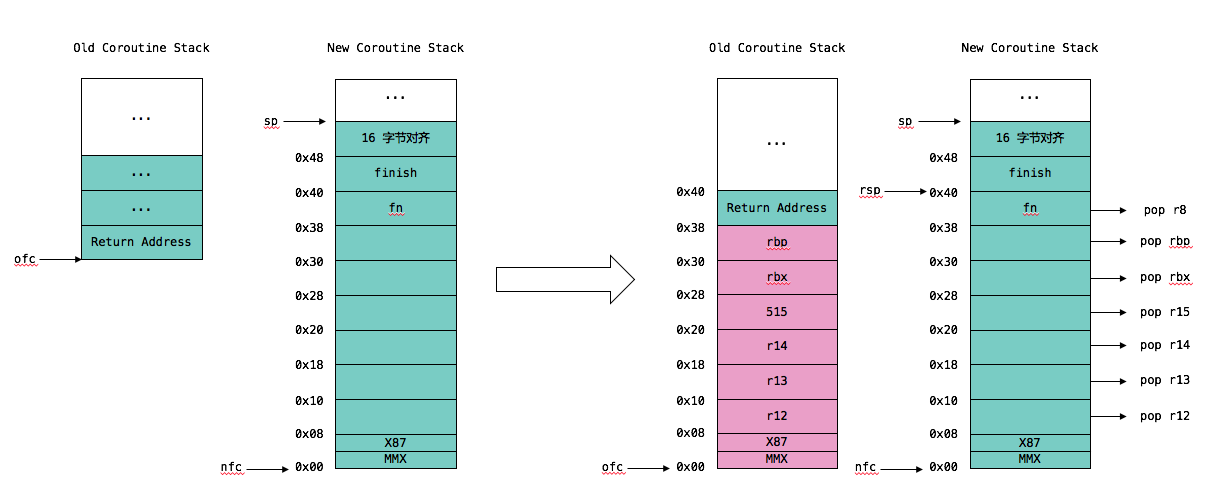
非首次调度是指该 Coroutine 已经运行过一段时间了,那么其 Stack Frame 就如上图右二所示,于是 Context Switch 意味着:
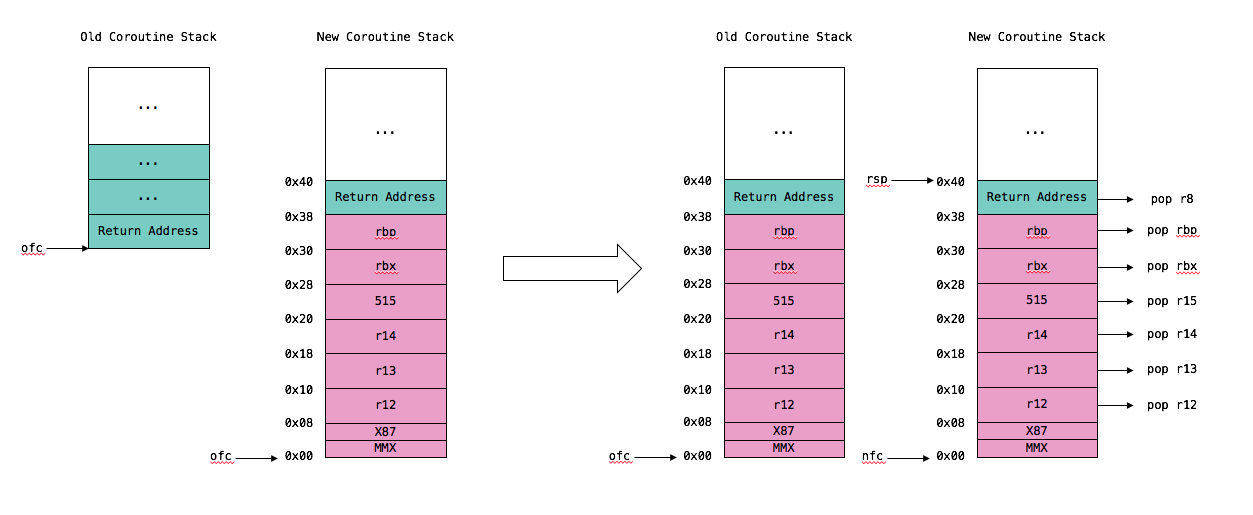
瞧!这里面最精妙的就是首次调度和非首次调度之间细微的差别。首次调度继续运行的地址(R8)就是 make context 时保存的 fn(协程入口函数,往往与调度器有关),非首次调度继续运行的地址(R8)则恰好就是我们在第 2 节(Stack Frame)一再强调的 Return Address,也就是协程被切换的位置。
boost.context 不愧是大师之作,实在是太精巧了!
4. More
到这里,读者应该明白了协程 Context Switch 到底是如何实现的,老实讲,不深入到汇编代码中也不会影响我们阅读协程库的实现,但是那种感觉就如隔靴搔痒,总是差了那么点意思。
从最微观的地方理解了上下文切换,继续思考协程栈、协程调度等上层细节才能做到心中自有丘壑。